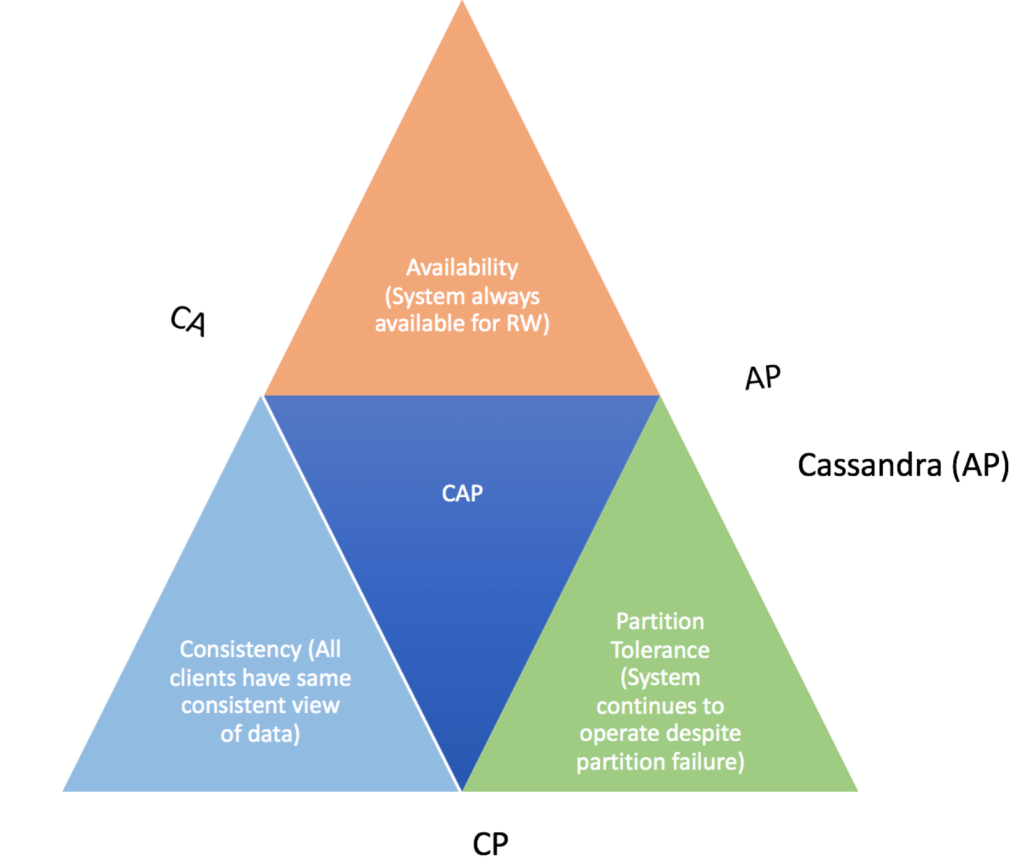
Before we begin, understand the CAP theorem
- CAP (Consistency, Availability and Partition Tolerance), the foundation behind the design of a distributed database system. The foundation of a distributed system is based on the CAP theorem (illustrated in the following diagram), which states that it is impossible for a distributed computing system to simultaneously guarantee Consistency, Availability and Partition Tolerance. Therefore, each distributed system must do some trade off and choose any two of these three properties.
- Per the CAP theorem, a distributed system can either guarantee Consistency and Availability (CA) while allowing some trade off with Partition Tolerance, or it can guarantee Consistency and Partition Tolerance (CP) while allowing some trade off with Availability or it can guarantee Availability and Partition Tolerance (AP) while allowing some trade off with Consistency.
- Cassandra is highly Available and Partition Tolerant distributed database system with tunable (eventual) Consistency. In Cassandra, we can tune the consistency on per query basis.
What is Cassandra database?
- The Apache Cassandra database is the right choice when you need scalability and high availability without compromising performance. Linear Scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.Cassandra’s support for replicating across multiple data centers is best-in-class, providing lower latency for your users and the peace of mind of knowing that you can survive regional outages.
- Proven: Cassandra is used at large corporations across the globe, for user cases from streaming media, retail, eCommerce, IoT that have large active data sets.
- Fault Tolerant: Data is automatically replicated to multiple nodes for fault-tolerance. Replication across multiple data centers is supported. Failed nodes can be replaced with no downtime.
- Performant: Cassandra consistently outperforms popular NoSQL alternatives in benchmarks and real applications, primarily because of fundamental architectural choices.
- Decentralized: There are no single points of failure. There are no network bottlenecks. Every node in the cluster is identical.
- Scalable: Some of the largest production deployments include Apple’s, with over 75,000 nodes storing over 10 PB of data, Netflix (2,500 nodes, 420 TB, over 1 trillion requests per day), Chinese search engine Easou (270 nodes, 300 TB, over 800 million requests per day), and eBay (over 100 nodes, 250 TB).
- Durable: Cassandra is suitable for applications that can’t afford to lose data, even when an entire data center goes down.
- Elastic: Read and write throughput both increase linearly as new machines are added, with no downtime or interruption to applications.
Architecture:
- Cassandra Cluster Ring:
- At a very high level, Cassandra operates by dividing all data evenly around a cluster of nodes, which can be visualized as a ring. Nodes generally run on commodity hardware. Each C* node in the cluster is responsible for and assigned a token range (which is essentially a range of hashes defined by a partitioner, which defaults to Murmur3Partitioner in C* v1.2+). By default this hash range is defined with a maximum number of possible hash values ranging from 0 to 2^127-1.
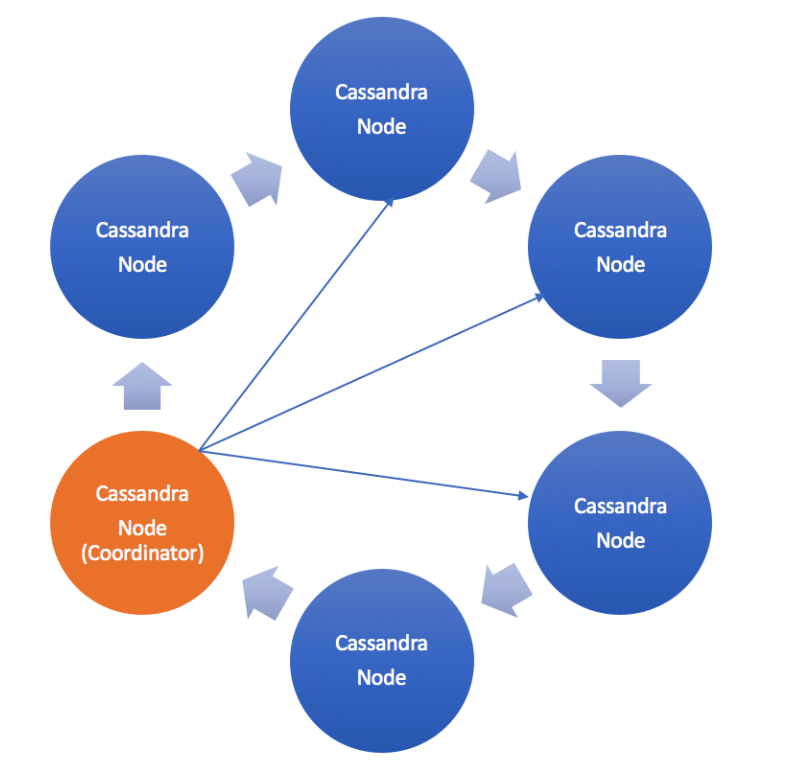
- In Cassandra, there is no master/slave concept. Each node (server) in a Cassandra cluster is treated or functions equally. A client read or write request can be routed to any node ( which acts as a coordinator for that particular client request) in the Cassandra cluster irrespective of the fact whether that node owns the requested/written data. Each node in the cluster exchange information (using a peer-to-peer protocol) across the cluster every second, which makes it possible for the nodes to know which node owns which data and status of other nodes in the cluster. If a node fails, any other available node will serve the client’s request. Cassandra guarantees availability and partition tolerance by replicating data across the nodes in the cluster. We can control the number of replicas (copies of data) to be maintained in the cluster through “Replication Factor”. There is no primary or secondary replica, each replica is equal and a client request can be served from any available replica.
- Cassandra Ring Token Distribution.
- One of Cassandra’s many strong points is its approach to keeping architecture simple. It is extremely simple to get a multi node cassandra cluster up and running. While this initial simplicity is great, Cassandra cluster will still require some ongoing maintenance throughout the life of your cluster.
- There are two main aspects of token management in Cassandra. The first and somewhat more straightforward aspect, is the initial token selection for the nodes in your cluster. The second aspect being the maintenance of nodes and tokens in the production cluster in order to keep the cluster balanced.
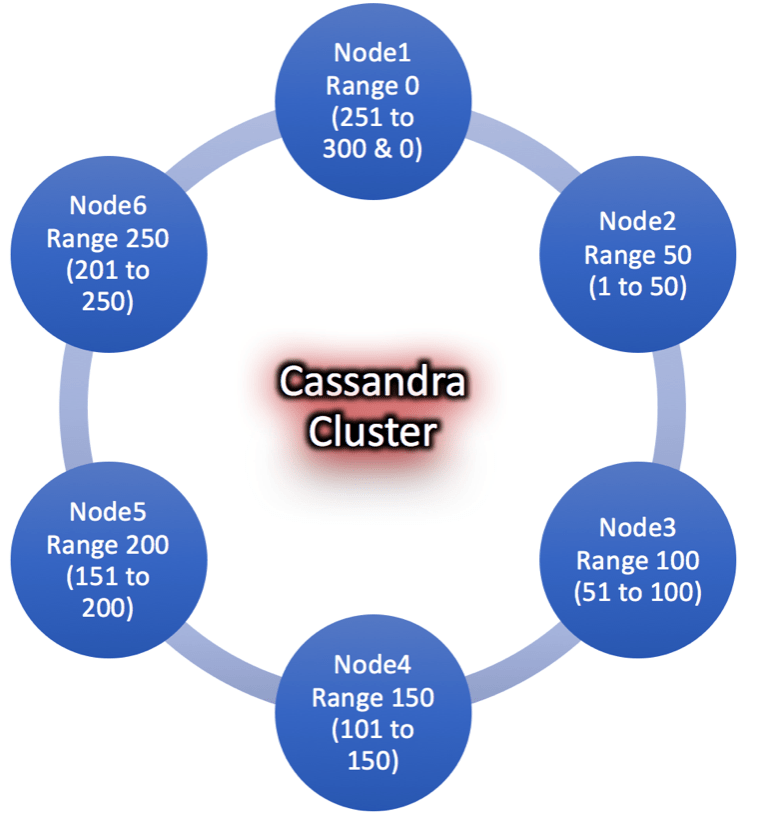
- Consistent hashing: The core of Cassandra’s peer to peer architecture is built on the idea of consistent hashing. This is where the concept of tokens comes from. The basic concept from consistent hashing for our purposes is that each node in the cluster is assigned a token that determines what data in the cluster it is responsible for. The tokens assigned to your nodes need to be distributed throughout the entire possible range of tokens. As a simplistic example, if the range of possible tokens was 0-300 and you had six nodes, you would want the tokens for your nodes to be: 0, 50, 100, 150, 200, 250.
- Initial Token Selection: The easiest time to ensure your cluster is balanced is during the intial setup of that cluster. Changing tokens once a cluster is running is a heavy operation that involves replicating data between nodes in the cluster.
- Balancing a Live Cluster:
- Determining the new tokens
- The first step in the process is to determine what the tokens in your cluster should be. At first glance this step may seem straightforward. Using the example above, if I have a token range of 300 and 6 nodes, my tokens should be: 0, 50, 100, 150, 200, 250. Actually though, this is just one set of possible tokens that are valid. It is really the distribution of the tokens that matters in this case. For example, the tokens 10, 60, 110, 160,210 and 260 will also provide a balanced cluster.
- Optimizing for the smallest number of moves
- In the case of balancing a live cluster, you want to find the optimal set of tokens taking into consideration the tokens that already exist in your cluster. This allows you to minimize the number of moves you need to do in order to balance the cluster. The process actually involves examining each token in the ring to see if it is ‘balanced’ with any other tokens in the ring.
- Optimizing for the smallest amount of data transferred
- After narrowing down the possible sets of new tokens for you cluster, it is possible that there may be multiple sets of tokens that can balance a cluster and require the same number of moves. In this case we want to further narrow down our options by picking the set of tokens that requires the last amount of data transfer in our cluster. That is, the set of tokens that require the shortest total distance to move.
- Dealing with multiple racks
- In order to achieve the best fault tolerance, it can be a good idea to distribute the data across multiple racks in a single datacenter. To achieve this in Cassandra, alternate racks when assigning tokens to your nodes. So token 0 is assigned to rack A, token 1 to rack B, token 2 to rack A, token 3 to rack B, etc. It is necessary to take this into account in the above two steps if you are dealing with a rack aware cluster.
- Moving the nodes
- At this point, we’ve determined the optimal set of new tokens, and the nodes in our cluster that need to move to these tokens. The rest of the process is fairly simple, but involves some additional Cassandra operations besides just the command to move tokens. Each move is done synchronously in the cluster. The first step is to initiate the move using the JMX method exposed by Cassandra. If you were doing this manually you would use the nodetool utility provided by Cassandra, which has a ‘move’ command. The move operation will involve transferring data between nodes in the cluster, but it does not automatically clean up data that nodes are no longer responsible for. After each move, we also need to tell Cassandra to cleanup the old data nodes are no longer responsible for. We need to cleanup the node that has just moved, as well as any nodes in the cluster that have changed responsibility. Internally OpsCenter determines these nodes by comparing the ranges each node was responsible for before the move, with the ranges each node is responsible for after the move.
- Determining the new tokens
- A
- Data distribution and Replication
- In Cassandra, data distribution and replication go together. Data is organized by table and identified by a primary key, which determines which node the data is stored on. Replicas are copies of rows. When datais first written, it is also referred to as a replica.
- Factors influencing replication:
- Virtual Nodes: assigns data ownership to physical machines
- Partitioner: partitions data across the cluster
- Replication Strategy: determines replicas for each row of data
- Snitch: defines the topology that the replication strategy uses to place replicas
- Data replication: Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed.
admin@ip-10-94-249-80:~$ nodetool getendpoints findb_uat custprofile 15e0b717-3c7f-436a-93eb-07e13b79b1b4
3.251.xxx.xx
3.250.xxx.xxx
3.249.xxx.xx - In a Cassandra cluster, the nodes need to be distributed throughout entire possible token range starting from -2^(63) to 2^(63) – 1. Each node in the cluster must be assigned a token range. This token range determines the position of the node in the token ring and it’s range of data. For instance, if we have a token ring ranging from 0 to 300 and have 6 nodes in the cluster, then the token range for the nodes would be 0, 50, 100, 150, 200, 250 and 300 respectively. The fundamental idea behind the token range is to balance the data distribution across the nodes in the cluster.
- Cassandra Write Path
- Cassandra is masterless a client can connect with any node in a cluster. Clients can interface with a Cassandra node using either a thrift protocol or using CQL. In the picture above the client has connected to Node 4. The node that a client connects to is designated as the coordinator, also illustrated in the diagram. The coordinators is responsible for satisfying the clients request. The consistency level determines the number of nodes that the coordinator needs to hear from in order to notify the client of a successful mutation. All inter-node requests are sent through a messaging service and in an asynchronous manner. Based on the partition key and the replication strategy used the coordinator forwards the mutation to all applicable nodes. In our example it is assumed that nodes 1,2 and 3 are the applicable nodes where node 1 is the first replica and nodes two and three are subsequent replicas. The coordinator will wait for a response from the appropriate number of nodes required to satisfy the consistency level. QUORUM is a commonly used consistency level which refers to a majority of the nodes.QUORUM can be calculated using the formula (n/2 +1) where n is the replication factor.
- Cassandra Read Path
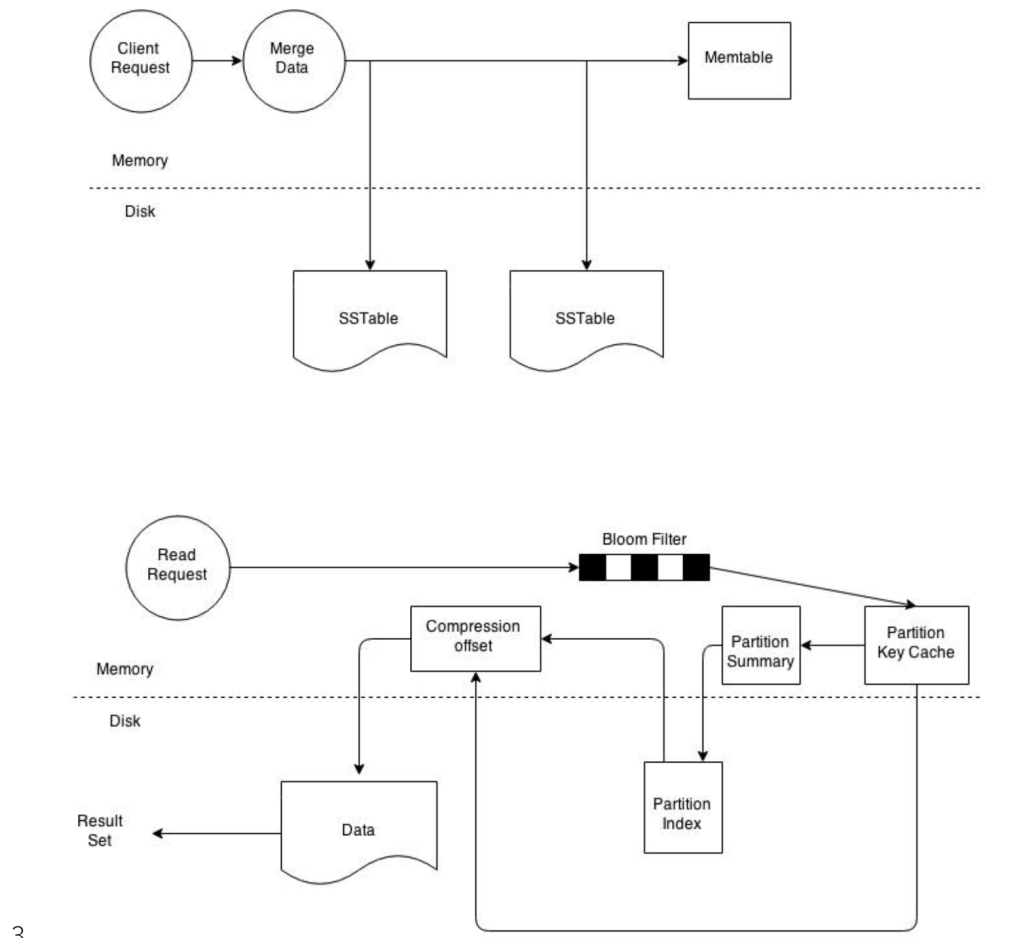
- To satisfy a read, Cassandra must combine results from the active memtable and potentially multiple SSTables.
- Cassandra processes data at several stages on the read path to discover where the data is stored, starting with the data in the memtable and finishing with SSTables:
- Check the memtable
- Check row cache, if enabled
- Checks Bloom filter
- Checks partition key cache, if enabled
- Goes directly to the compression offset map if a partition key is found in the partition key cache, or checks the partition summary if notIf the partition summary is checked, then the partition index is accessed
- Locates the data on disk using the compression offset map
- Fetches the data from the SSTable on disk
Key Terms and Concepts (Cassandra 101):
- Cluster: is the largest unit of deployment in Cassandra. Each cluster consists of nodes from one or more distributed locations (Availability Zones).
- Distributed Location: contains a collection of nodes that are part of a cluster. In general, while designing a Cassandra cluster on AWS, we recommend that you use multiple Availability Zones to store your data in the cluster. You can configure Cassandra to replicate data across multiple Availability Zones, which will allow your database cluster to be highly available even during the event of an Availability Zone failure. To ensure even distribution of data, the number of Availability Zones should be a multiple of the replication factor. The Availability Zones are also connected through low-latency links, which further helps avoid latency for replication.
- Node: is a part of a single distributed location in a Cassandra cluster that stores partitions of data according to the partitioning algorithm.
- Commit Log: is a write-ahead log (WAL) on every node in the cluster. Every write operation made to Cassandra is first written sequentially to this append-only structure, which is then flushed from the write-back cache on the operating system (OS) to disk either periodically or in batches. In the event of a node recovery, the commit logs are replayed to perform recovery of data. This is similar to PostgreSQL “wal” files or Oracle redo logs.
- Memtable: is basically a write-back cache of data rows that can be looked up by key. It is an in-memory structure. A single memtable only stores data for a single table and is flushed to disk either when node global memory thresholds have been reached, the commit log is full, or after a table level interval is reached.
- SStable: An SStable (sorted string table) is a logical structure made up of multiple physical files on disk. An SStable is created when a memtable is flushed to disk. An SStable is an immutable data structure. Memtables are sorted by key and then written out sequentially to create an SStable. Thus, write operations in Cassandra are extremely fast, costing only a commit log append and an amortized sequential write operation for the flush. Unlike most of RDBMS database typical OLTP workloads are random in nature which cause disk seeks, Cassandra avoids such random disks seek by pre-sorted on key when it store data that further helps avoids seeks during reads.
- Bloom Filter: is a probabilistic data structure for testing set membership that never produces a false negative, but can be tuned for false positives. Bloom filters are off-heap structures. Thus, if a bloom filter responds that a key is not present in an SStable, then the key is not present, but if it responds that the key is present in the SStable, it might or might not be present. Bloom filters can help scale read requests in Cassandra. Bloom filters can also save additional disk read operations reading the SStable, by indicating if a key is not present in the SStable.
- Index File: maintains the offset of keys into the main data file (SStable). Cassandra by default holds a sample of the index file in memory, which stores the offset for every 128th key in the main data file (this value is configurable). Index files can also help scale read operations better because they can provide you the random position in the SStable from which you can sequentially scan to get the data. Without the index files, you need to scan the whole SStable to retrieve data.
- Keyspace: is a logical container in a cluster that contains one or more tables. Replication strategy is typically defined at the keyspace level.
- Table: also known as a column family, is a logical entity within a keyspace consisting of a collection of ordered columns fetched by row. Primary key definition is required while defining a table.
- Data Partitioning: Cassandra is a distributed database system using a shared nothing architecture. A single logical database is spread across a cluster of nodes and thus the need to spread data evenly amongst all participating nodes. At a 10000 foot level Cassandra stores data by dividing data evenly around its cluster of nodes. Each node is responsible for part of the data. The act of distributing data across nodes is referred to as data partitioning.
- Consistent Hashing: Two main problems crop up when trying to distribute data efficiently. One, determining a node on which a specific piece of data should reside on. Two, minimizing data movement when adding or removing nodes. Consistent hashing enables us to achieve these goals. A consistent hashing algorithm enables us to map Cassandra row keys to physical nodes. The range of values from a consistent hashing algorithm is a fixed circular space which can be visualized as a ring. Consistent hashing also minimises the key movements when nodes join or leave the cluster. On average only k/n keys need to be remapped where k is the number of keys and n is the number of slots (nodes). This is in stark contrast to most hashing algorithms where a change in the number of slots results in the need to remap a large number of keys.
- Data Replication: Partitioning of data on a shared nothing system results in a single point of failure i.e. if one of the nodes goes down part of your data is unavailable. This limitation is overcome by creating copies of the data, know as replicas, thus avoiding a single point of failure. Storing copies of data on multiple nodes is referred to as replication. Replication of data ensures fault tolerance and reliability.
- Eventual Consistency: Data is replicated across nodes, we need to ensure that data is synchronized across replicas. This is referred to as data consistency. Eventual consistency is a consistency model used in distributed computing. It theoretically guarantees that, provided there are no new updates, all nodes/replicas will eventually return the last updated value. Domain Name System (DNS) are a good example of an eventually consistent system.
- Tunable Consistency: enables users to configure the number of replicas in a cluster that must acknowledge a read or write operation before considering the operation successful. The consistency level is a required parameter in any read and write operation and determines the exact number of nodes that must successfully complete the operation before considering the operation successful.
- Data Center, Racks, Nodes: A Data Centre (DC) is a centralized place to house computer and networking systems to help meet an organization’s information technology needs. A rack is a unit that contains multiple servers all stacked one on top of another. A rack enables data centers to conserve floor space and consolidates networked resources. A node is a single server in a rack. Why do we care? Often Cassandra is deployed in a DC environment and one must replicate data intelligently to ensure no single point of failure. Data must be replicated to servers in different racks to ensure continued availability in the case of rack failure. Cassandra can be easily configured to work in a multi DC environment to facilitate fail over and disaster recovery. At IBM Cloud Video Cassandra clusters are setup as follows
- Data Center – AWS region
- Rack – AWS Availability Zone (AZ)
- Node – EC2 in AZ
- Snitches and Replication Strategies: It is important to intelligently distribute data across DC’s and racks. In Cassandra the distribution of data across nodes is configurable. Cassandra uses snitches and replication strategies to determine how data is replicated across DC’s, racks and nodes. Snitches determine proximity of nodes within a ring. Replication strategies use proximity information provided by snitches to determine locality of a particular copy. At IBM Cloud Video Cassandra clusters, we use Ec2MultiRegionSnitch.
for example: endpoint_snitch: org.apache.cassandra.locator.Ec2MultiRegionSnitch
for more information about Cassandra snitches, see reference section. - Gossip Protocol: Cassandra uses a gossip protocol to discover node state for all nodes in a cluster. Nodes discover information about other nodes by exchanging state information about themselves and other nodes they know about. This is done with a maximum of 3 other nodes. Nodes do not exchange information with every other node in the cluster in order to reduce network load. They just exchange information with a few nodes and over a period of time state information about every node propagates throughout the cluster. The gossip protocol facilitates failure detection.
- Merkel Tree: is a hash tree which provides an efficient way to find differences in data blocks. Leaves contain hashes of individual data blocks and parent nodes contain hashes of their respective children. This enables efficient way of finding differences between nodes.
- Write Back Cache: A write back cache is where the write operation is only directed to the cache and completion is immediately confirmed. This is different from Write-through cache where the write operation is directed at the cache but is only confirmed once the data is written to both the cache and the underlying storage structure.
- Virtual Nodes: Virtual nodes, known as Vnodes, distribute data across nodes at a finer granularity than can be easily achieved if calculated tokens are used. Vnodes simplify many tasks in Cassandra:
- Tokens are automatically calculated and assigned to each node.
- Rebalancing a cluster is automatically accomplished when adding or removing nodes. When a node joins the cluster, it assumes responsibility for an even portion of data from the other nodes in the cluster. If a node fails, the load is spread evenly across other nodes in the cluster.
- Rebuilding a dead node is faster because it involves every other node in the cluster.
- The proportion of vnodes assigned to each machine in a cluster can be assigned, so smaller and larger computers can be used in building a cluster.
- Partitioner: A partitioner determines how data is distributed across the nodes in the cluster (including replicas). Basically, a partitioner is a function for deriving a token representing a row from its partition key, typically by hashing. Each row of data is then distributed across the cluster by the value of the token.
- Murmur3Partitioner
- RandomPartitioner
- ByteOrderPartitioner
Best Practices and Considerations:
- Configuring data consistency:
- Consistency refers to how up-to-date and synchronized a row of Cassandra data is on all of its replicas. Cassandra extends the concept of eventual consistency by offering tunable consistency. For any given read or write operation, the client application decides how consistent the requested data must be.
- Consistency levels in Cassandra can be configured to manage availability versus data accuracy. Configure consistency for a session or per individual read or write operation. Within cqlsh, use CONSISTENCY, to set the consistency level for all queries in the current cqlsh session. For programming client applications, set the consistency level using an appropriate driver. For example, using the Java driver, call QueryBuilder.insertInto with setConsistencyLevel to set a per-insert consistency level.
- For more information refer: https://lake.data.blog/2020/02/16/how-the-cassandra-consistency-level-configured/
- Cassandra Data Model.
- Cassandra data model by Queries.
- Cassandra data model works queries by design. Know your queries before hand and evolve data model based on how you are going to query the tables.
- Cassandra data model by Queries.
Cassandra Ring in AWS
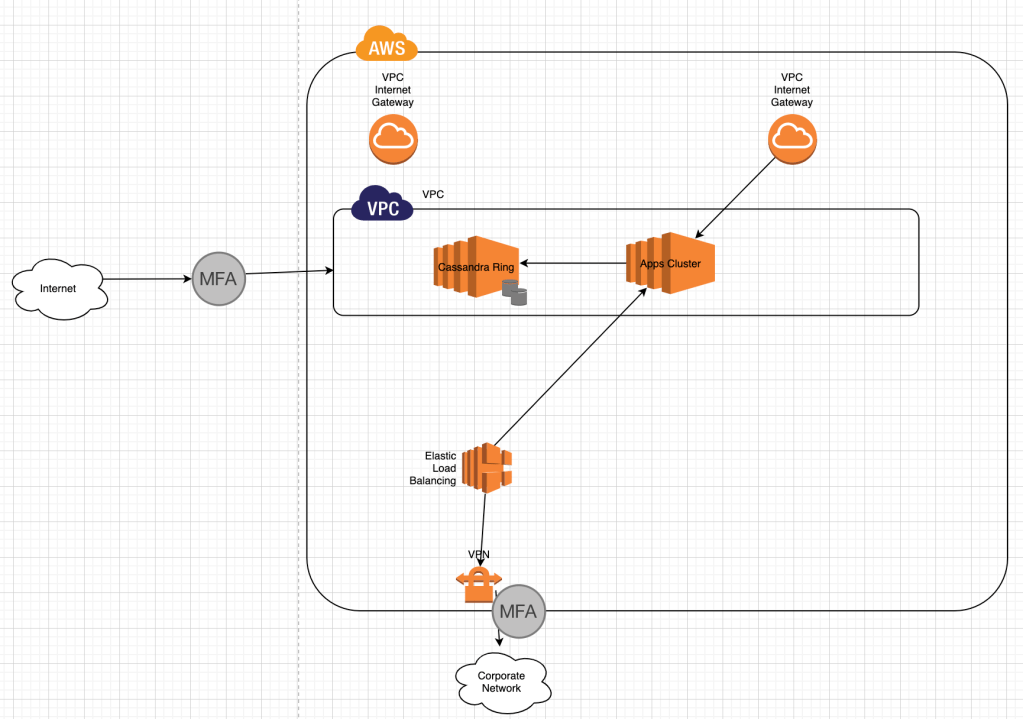
Performance Tuning:
- Cassandra Garbage Collector tuning
- Refer:
- Long GC pauses
- Refer:
- Aggressive Compactions
- Cassandra Heap Pressure Scenarios
- Compaction
- The Cassandra write process stores data in files called SSTables. SSTables are immutable. Instead of overwriting existing rows with inserts or updates, Cassandra writes new timestamped versions of the inserted or updated data in new SSTables. Cassandra does not perform deletes by removing the deleted data: instead, Cassandra marks it with tombstones.
- Over time, Cassandra may write many versions of a row in different SSTables. Each version may have a unique set of columns stored with a different timestamp. As SSTables accumulate, the distribution of data can require accessing more and more SSTables to retrieve a complete row.
- To keep the database healthy, Cassandra periodically merges SSTables and discards old data. This process is called compaction.
- Compaction works on a collection of SSTables. From these SSTables, compaction collects all versions of each unique row and assembles one complete row, using the most up-to-date version (by timestamp) of each of the row’s columns. The merge process is performant, because rows are sorted by partition key within each SSTable, and the merge process does not use random I/O. The new versions of each row is written to a new SSTable. The old versions, along with any rows that are ready for deletion, are left in the old SSTables, and are deleted as soon as pending reads are completed.
- Compaction causes a temporary spike in disk space usage and disk I/O while old and new SSTables co-exist. As it completes, compaction frees up disk space occupied by old SSTables. It improves read performance by incrementally replacing old SSTables with compacted SSTables. Cassandra can read data directly from the new SSTable even before it finishes writing, instead of waiting for the entire compaction process to finish.
- As Cassandra processes writes and reads, it replaces the old SSTables with new SSTables in the page cache. The process of caching the new SSTable, while directing reads away from the old one, is incremental — it does not cause a the dramatic cache miss. Cassandra provides predictable high performance even under heavy load.
- Compaction Types:
- SizeTieredCompactionStrategy (STCS)
- Recommended for write-intensive workloads.
- Pros:Compacts write-intensive workload very well
- Cons: Can hold onto stale data too long. Amount of memory needed increases over time.
- LeveledCompactionStrategy (LCS)
- Recommended for read-intensive workloads.
- Pros: Disk requirements are easier to predict. Read operation latency is more predictable. Stale data is evicted more frequently.
- Cons: Much higher I/O utilization impacting operation latency
- TimeWindowCompactionStrategy(TWCS)
- Recommended for time series and expiring TTL workloads.
- Pros: Used for time series data, stored in tables that use the default TTL for all data. Simpler configuration than that of DTCS.
- Cons: Not appropriate if out-of-sequence time data is required, since SSTables will not compact as well. Also, not appropriate for data without a TTL, as storage will grow without bound. Less fine-tuned configuration is possible than with DTCS.
- DateTieredCompactionStrategy(DTCS)
- Deprecated in Cassandra 3.0.8/3.8.
- Pros: Specifically designed for time series data, stored in tables that use the default TTL. DTCS is a better choice when fine-tuning is required to meet space-related SLAs.
- Cons: Insertion of records out of time sequence (by repairs or hint replaying) can increase latency or cause errors. In some cases, it may be necessary to turn off read repair and carefully test and control the use of TIMESTAMP options in BATCH, DELETE, INSERT and UPDATE CQL commands.
- SizeTieredCompactionStrategy (STCS)
Tools & Maintenance:
Cassandra Tools & Maintenancehttps://lake.data.blog/2020/02/16/cassandra-tools-maintenance/
Troubleshooting:
- nodetool –
- dstat
- htop, top, strace
- lsof
- jvisualvm
- jps
- nodetool (https://lake.data.blog/2020/02/16/cassandra-nodetool/)
Cassandra Stress Test
Cassandra-stress tool is java base stress testing utility for basic benchmarking and load testing a Cassandra cluster. Data modeling choices will affect application performance. Significant load testing over several trials is the best way to discover issues with specific data model. The cassandra-stress tool is an effective tool for populating a cluster and stress testing CQL tables and queries. Use cassandra-stress to:
- Quickly determine how a schema performs.
- Understand how your database scales.
- Optimize data model and settings
- Determine production capacity
- Supports YAML based profile to defining specific schemas with various compaction strategies, cache settings and types.
- YAML file supports user-defined keyspaces, tables and schema.
